I like to take baby steps when it comes to learning new things. Otherwise I would get so stressed out that I'd end up anxiously eating Cheetos, in hopes that my cheese-coated fingers would give me a semi-legitimate excuse not to have to type for a while.

So while I was conducting research for a series of articles about Elasticsearch, I began to wonder how I could learn a bit more about something new (Elasticsearch) by packaging it with something that I already know I like (Python). And thus Elasticsnoop was born!
The full scoop on Elasticsnoop
Elasticsnoop is a simple Flask app that uses the pyelasticsearch client to search a locally hosted Elasticsearch index. You may wonder...why bother? After all, it doesn't have a lot of the functionality that Elasticsearch's Sense plugin does. What is this? Non-sense? Why, yes, yes it is.
Basically, I created it because I didn't see many Python/Flask + Elasticsearch projects out there, and I thought it might help or inspire a kindred spirit who wants to experiment with these two technologies. And that's as good a reason as any to create something, right?
Now let's get to the good stuff.
How to set up a Flask app & Elasticsearch index
Set up Elasticsearch
Download Elasticsearch and start it up on your machine. Make sure it's running (curl localhost:9200 should return some JSON that ends with "you know, for search"):
{
"name" : "my_node",
"cluster_name" : "my_cluster",
"version" : {
"number" : "2.3.3",
"build_hash" : "bla bla bla",
"build_timestamp" : "2016-05-17T15:40:04Z",
"build_snapshot" : false,
"lucene_version" : "5.5.0"
},
"tagline" : "You Know, for Search"
}
Keep it running while you proceed with the steps below. (When you're done with this tutorial you can exit Elasticsearch with a ctrl + C.
Prepare your data
Now that we have Elasticsearch up and running locally, it's time to prepare some data that we can store in an ES index. See this post for some basic pyelasticsearch commands, or consult more details in final notes. My data was stored in JSON file in this format:
[
{
"Content": "words, words, words...",
"Tags": [
"integration",
"apache",
"java",
"jmx",
"tomcat",
"web server"
],
"Author": "Abril Loya Enriquez",
"Title": "Monitor Tomcat metrics with Datadog"
},
{
"Content": "more words, more words, more words",
"Tags": [
"integration",
"monitoring",
"performance",
"python",
"wsgi server"
],
"Author": "Emily Chang",
"Title": "Monitor Gunicorn performance with Datadog"
},
{
more docs...
}
]
Upload the data into your index
It's time to index your JSON documents. Here's how I indexed my file, using pyelasticsearch (note the capital S in ElasticSearch). The file is called my_data.json in the code snippet below, and is stored in the same directory from which we're running this script.
import json
from pyelasticsearch import ElasticSearch
def load_data():
# use default localhost:9200 to connect to Elasticsearch client
# replace with your own IP/port in ElasticSearch() as needed
es = ElasticSearch()
output_json = json.load(open('my_data.json'))
# create mapping for our index
my_mapping = {
"my_type": {
"properties": {
"Content": {"type": "string"},
"Tags": {"type": "string", "index": "not_analyzed"},
"Author": {"type": "string", "index": "not_analyzed"},
"Title": {"type": "string"}
}
}
}
# create the index, my_index, using the mapping we created
es.create_index('test_tweets', settings={'mappings': my_mapping})
es.bulk((es.index_op(doc) for doc in output_json), doc_type='my_type', index='my_index')
return True
Note that although we created a mapping for our document type, my_type, this is not a requirement when using Elasticsearch. If you don't specify mappings for any of your doc types before creating your index, once you start uploading data, Elasticsearch will automatically detect the type of each field (date, string, integer, etc.).
However, if you want to ensure that Elasticsearch stores your data the way you intend it to be stored, you should probably create a mapping for your index.
For example, I chose to make the "Author" field not_analyzed because the authors aren't going to appear differently (for example, the blog isn't going to list the author as Emily Chang in one post and just emily on another post. It's an automatically generated field that shouldn't vary from post to post. We also may want to be able to aggregate on it later, which means we can take advantage of doc values, which do not work on analyzed string fields.
Get Elasticsnoopin'
Clone the Elasticsnoop repo.
Create a virtual environment and install the requirements: pip install -r requirements.txt.
Now you need to make a few changes to a few files in your local ElasticSnoop repo. Open up elasticsnoop.py and replace index_name (in the get_search_query() function) with the name of the index you created.
- In templates/search_results.html, tweak this section:
{% for doc in results['hits']['hits'] %}
<p>{{ doc['_source']['Title'] }}</p>
{% endfor %}
...by replacing doc['_source']['Title'] with the name of the field you want to see in the results (e.g. doc['_source']['category'] if the desired field is 'category').
Save your changes and fire up Flask (run python elasticsnoop.py from your elasticsnoop directory and navigate to 127.0.0.1:5000 in your favorite web browser).
You should now be able to start searching your Elasticsearch index by typing stuff into the search bar on the Elasticsnoop homepage.
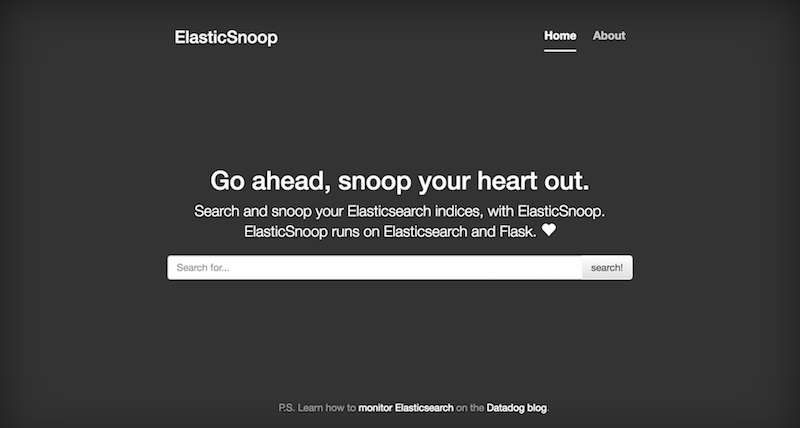
What it looks like
Here's the homepage:
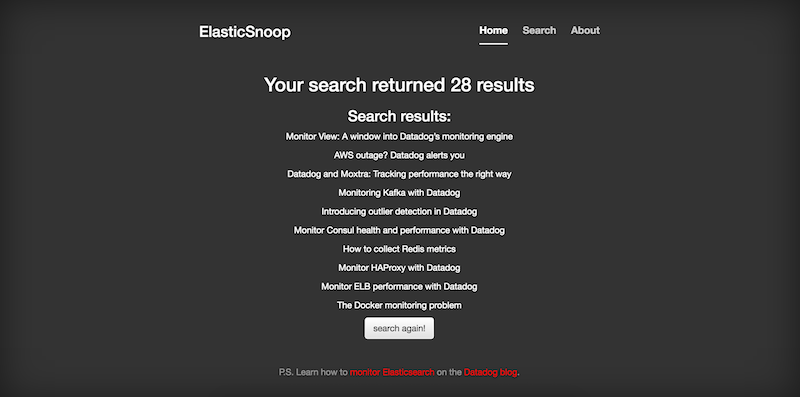
And the search results page:
Some closing questions you might have
What data should I use for my index?
Anything you want! I used Selenium to scrape some blog posts and stored them as JSON. You can also download existing datasets from somewhere like Data is Plural and just use those if you want to get started right away. Elasticsearch's Kibana tutorial also includes a Shakespeare JSON file you can download.
I got my Flask app working, but the functionality is kind of limited. What now?
This very simple version assumes you only want to search one ES index, and see how many results/hits you get. In reality, you probably want to do much more! Feel free to revise elasticsnoop.py by modifying get_search_query() to support more complex queries. Consult the pyelasticsearch docs for more info on that. You can also create multiple Elasticsearch indices, or and update the Flask code to enable the user to specify which index to search.
Happy Elasticsnooping!